Data Mining
Our data mining research started in the early 90s and
span over the past decade. The broad scope of our research was motivated
by real problem domain which includes:
1. Data Mining Algorithms:
- Clustering of non-numerical and numerical attribute values for query relaxation
- Multivariate classification for data with large attribute space
- Temporal Data Mining
- Mining MFI (Maximum Frequent Item Sets) for association rules
2. Selected Data Mining Applications
In this experiment we shall show MQuery tool to construct a sequence query then using our
approximate sequence matching technology to generate a set of matched sequences, which are
ranked according to the nearest measure as shown in the following set of figures.
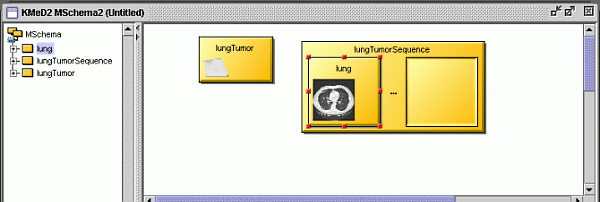 Fig. 1 shows the lung tumor sequence template.
Query 1: Query Sequence with two images
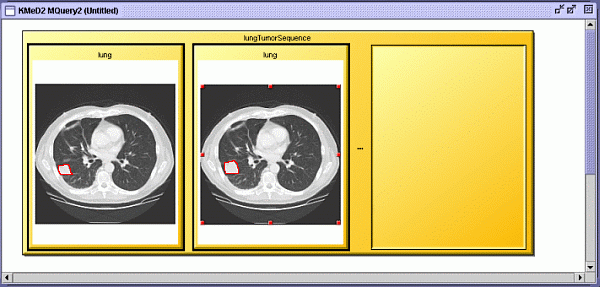
Fig. 2 A query sequence of two CT lung images showing a tumor growing, constructed from the template in fig 1. Executing the query returns a result viewer window with which we can view the results of the query.

Fig. 3 KMeD searches the sequence database with the approximate matching technique and the
best results are returned and shown in the Result Viewer. The features used for the lung tumor
are the distance from the x and y centroid, and lung tumor area. The features which are
represented in a column. The first four columns represent the features for the first image,
and the next four represent the features of the second image. The distance is the nearness of
the answer sequence with the target sequence. Each row represents an answer, their ranked
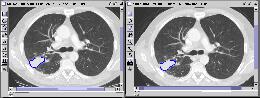
according the distance. The corresponding first three image result sequences are shown in
Figure 4.
|
|
|
|
First query result |
Second query result |
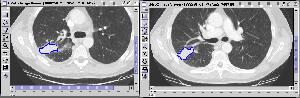 Third query result Figure 4 Query 2: Query Sequence with three images

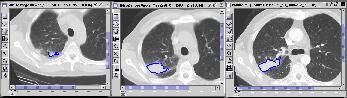
Figure 5 A query sequence of three CT lung images showing a tumor growing, constructed from the template in fig 1.

Figure 6 KMeD searches the sequence database with the approximate matching technique and the best
results are returned and shown in the Result Viewer. The features used for the lung tumor are the
distance from the x and y centroid, and lung tumor area. The features which are represented in a column.
The first four columns represent the features for the first image, and the next four represent the
features of the second image, and the next four represent the features of the third image. The distance
is the nearness of the answer sequence with the target sequence. Each row represents an answer, their
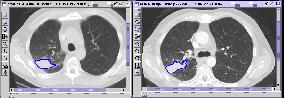
ranked according the distance. The corresponding first two image result sequences are shown in Figure 7.
 First Result of Query
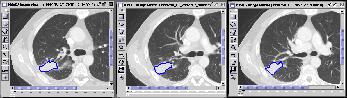 Second Result of Query Figure 7
- MEMS sensors and actuators
- Dynamic control
- Delta wing flight control
- Temporal and spatial data mining
3. References
- Yu Chen, Lars Henning Pedersen, Wesley W. Chu and Jorn Olsen. "Drug Exposure Side Effects from Mining Pregnancy Data" In SIGKDD Explorations (Volume 9, Issue 1), June 2007, Special Issue on Data Mining for Health Informatics, Guest Editors: Raymond Ng and Jian Pei
-
Qinghua Zou, Wesley W. Chu, Yu Chen, and Xinchun Lu.
"Mining association rules from tabular data guided by maximal frequent itemset.
In W.W. Chu and T.Y. Lin, editors, Foundations and Advances in Data Mining.Springer, 2005.
- Zou, Q. and W. W. Chu "Mining Frequent Patterns via Pattern
Decomposition", Encyclopedia of Data Warehousing and Mining , Springer,
2005
- Zou, Q., W. W. Chu, D. Johnson, H. Chiu, "Pattern
Decomposition Algorithm for Data Mining of Frequent Patterns",
International Journal on Knowledge and Information Systems (KAIS), pps. 1-14,
2002.
- Zou, Q., W. W. Chu, and B. Lu. "SmartMiner: A Depth First
Algorithm Guided by Tail Information for Mining Maximal Frequent
Itemsets", Proceedings of the IEEE International Conference on Data Mining, Japan,
Dec 2002
- Giuffrida, G., W. W. Chu., and D. M. Hanssens, "NOAH: An
Algorithm for Mining Classification Rules from Datasets with Large Attribute
Space", Proceedings of the 12th International Conference on Extending
Database (EDBT), Konstanz, Germany, pps. 1-20, March 27-31,
2000.
- Park, S. and W. W. Chu,
"Discovering and Matching Elastic Rules from Sequence Databases",
Fundamenta Informaticae Journal, pps. 1-16, 2001.
- Goldman, J.A., W. W. Chu, D. S. Parker, and R. M. Goldman,
"Term Domain Distribution Analysis: a Data Mining Tool for Text
Databases", 2001 IMIA Yearbook of Medical Informatics, Schattauer, Stuttgart, Germany,
pps. 96-101, 2001.
- Merzbacher, M. A. and W. W. Chu, "Pattern-Based Clustering
For Database Attribute Values", AAAI Workshop on Knowledge Discovery in
Databases, Washington, D.C., pps. 1-8, 1993.
|
