Query Relaxation for XML Database
Project funded NSF Award # 0219442
1. Project Overview
1.1 Project Introduction & Motivation
As the World Wide Web becomes a major means of disseminating and sharing information, there
has been an exponential increase in the amount of data in web-complaint format
such as HyperText Markup Language (HTML) and Extensible Markup Language (XML).
XML is essentially a text representation of hierarchical (tree-like) data where
a meaningful piece of data is bounded by matching starting and ending tags, such
as <name> and </name>. Due to its simplicity as compared to SGML and
its relative expressiveness as compared to HTML, XML has become a popular
format for information representation and data exchange.
To cope with the tree-like structures in the XML model, several
XML-specific query languages have been proposed (e.g. XPath, XQuery,
etc.). All these query languages aim at the exact matching of query conditions. Answers
are found when those XML documents match the given query condition exactly.
However, this may not always be the case in the XML model. To remedy this
condition, we propose to develop a query relaxation framework for searching
answers that approximately match the given query conditions. Query relaxation
enables systems to relax the user query to a less restricted form to devise
approximate answers.
In the XML domain, because of the flexible nature of the XML model allows varied structures and/or values
and the non-rigid XML tag syntax enables to embed a wealth of meta information in XML documents,
the need for such query relaxation increases. The following points illustrates that query
relaxation is more important for the XML model than the relational model:
- Unlike in the relational model where users are given a relatively small-sized schema to ask queries, the schema in the XML model is substantially bigger and more complex. Therefore, it is often unrealistic for users to understand the full schema and compose very complex queries at once. Therefore, it becomes critical to be able to relax the user's query when the original query yields null or not sufficient answers.
- As the number of data sources available on the web increases, it becomes common to build a system where data is gathered from heterogeneous data sources and where the structures of the participating data sources are different, even though they are using the same ontology. Therefore, the capability to query against differently-structured data sources becomes more important. Query relaxation allows the query
to be structurally relaxed and routed to diverse data sources with different structures.
We propose a cooperative XML (CoXML) system for approximate
query answering. The objective of CoXML is to develop an XML query relaxation
enabled search engine such that when users' queries have empty or insufficient
answers, our system can relax the queries to get approximate answers.
1.2 Summary of Approaches
CoXML is based on the following two key techniques:
- Extending the standard XQuery with relaxation constructs and
controls. Such a relaxed XQuery (RLXQuery) language enable users to specify
relaxation constructs (e.g., approximate, preferred, unacceptable query
conditions etc.), and relaxation controls (e.g., relaxation orders, answer
set size, etc.).
- Using a knowledge-based relaxation index XML Type Abstraction Hierarchy
(XTAH), to guide the XML query relaxation process. XTAH is a hierarchical
tree-like multi-level knowledge structure where similar XML fragments are
clustered based on the inter XML fragment distance measure. An XTAH has two
node types: internal nodes and leaf nodes. An internal node has a
representative tree that summarizes the characteristics, including the
structure and semantics, of all the XML fragments in that cluster. A leaf
node has a representative tree as well as a set of XML fragments that are
similar to each other. Guided by the XTAH, based on the relaxation constructs
in RLXQuery, CoXML processes the query and returns approximately matched
answers.
1.3 CoXML System Overview
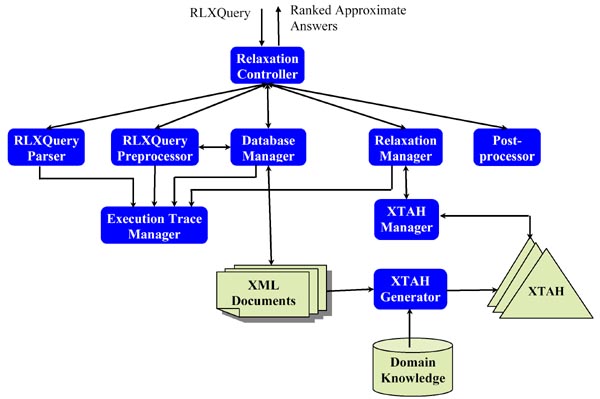
The diagram above illustrates the architecture of our CoXML system, which consists of
a relaxation controller, a RLXQuery parser, a RLXQuery preprocessor, a database
manager, a relaxation manager, an XTAH manager, an XTAH generator, an execution
trace manager and a post-processor. The functionalities of
each module are briefly described as follows:
- XTAH Generator
Given a set of XML documents and some domain knowledge, the
XTAH generator automatically generates XTAHs that summarize the content
and structure characteristics of the underlying XML documents.
- Relaxation Controller
The relaxation controller is the main interface to the outside world.
The controller is the controlling unit of RLXQuery search engine and it
dispatches the query to different modules to allow them to perform some
specific task to the query. It is the module that decides when to stop
query relaxation based on the criteria specified by the user.
- RLXQuery Parser
The RLXQuery Parser transforms an RLXQuery into an XQueryRep object.
The Query Parser performs two services. The first part is responsible for
checking the syntax of the query. If the syntax is correct, then the
query is parsed to the second part. The second part extracts all the in
formation from the query and creates an XQueryRep object.
- RLXQuery Preprocessor
The RLXQuery Preprocessor transforms relaxation constructs (if any) in the query into the standard XQuery constructs and
communicates with the database manager to check whether there are
enough answers available. If not, the relaxation controller will send the query to the relaxation manager.
- Database Manager
The functionality of the database manager is to find exact matched answers to a standard XQuery.
- Relaxation Manager
The relaxation manager performs the following functionalities: 1) building a relaxation structure based on the specified relaxation constructs and controls;
2)communicating with the XTAH manager to get relaxed conditions; and 3)modifying the query accordingly.
- XTAH Manager
The functionality of the XTAH manager is to select an appropriate XTAH for guiding the query relaxation process.
- Post-processor
The functionality of the post-processor is to accept unsorted answers and output these answers in a ranked order.
- Execution Trace Manager
The Execution Trace keeps track of all the actions incurred on the XQueryRep by each module. All modules need to communicate with the Execution Trace to record their changes to the XQueryRep.
- Ranking of approximate answers
A model has been developed to rank answers based on both content and structure relaxation.
2. Screenshots Examples
Example of using a GUI interface to help users to specify relaxations in queries
3. Members
| Wesley W. Chu |
Principal Investigator |
wwc AT cs.ucla.edu |
| Shaorong Liu |
Ph.D. Student |
sliu AT cs.ucla.edu |
| Ruzan Shahinian |
M.S. Student |
|
| Joseph Chen |
M.S. Student |
jccs05 AT gmail.com |
| Christian Cardenas |
M.S. Student |
|
| Anna Putnam |
M.S. Student |
|
| Eric Sung |
M.S. Student |
|
| Tony Lee |
M.S. Student |
|
4. Publications
4.1 Papers
- Shaorong Liu and Wesley W. Chu. CoXML: A Cooperative XML Query Answering System. In the 8th International Conference on Web-Age Information
Management, 2007. (Paper in PDF format)
- Wesley W. Chu and Shaorong Liu. CoXML: Cooperative XML Query Answering
In The Encyclopedia of Computer Science and Engineering, Edit by B. Wah, John Wiley & Sons, Inc, 2007, to appear
(Paper in PDF format)
- Shaorong Liu, Wesley W. Chu, and Ruzan Shahinian. Vague Content and Structure (VCAS) Retreival for Document-centric XML Collections. In WebDB (in conjunction with SIGMOD), 2005. (Paper in PDF format)
- Shaorong Liu, Qinghua Zou, and Wesley W. Chu. Configurable Indexing and
Ranking for XML Information Retrieval.In
Proceedings of 27th Annual International ACM SIGIR Conference,
2004. (Paper in PDF format, slides in power point format)
- Shaorong Liu and Wesley W. Chu. Cooperative XML (CoXML) Query Answering at INEX 2003.
In Proceedings of the 2nd INitiative
of the Evaluation of XML retrieval (INEX) Workshop, Schloss Dagstuhl,
Germany,2003. PDF
-
Qinghua. Zou, Shaorong Liu, and Wesley W. Chu.
Using a Compact Tree to Index and Query XML Data. In Proceedings of
Thirteenth Conference on Information and Knowledge Management (CIKM), 2004.
PDF
- Qinghua. Zou, Shaorong Liu,
and Wesley W. Chu. Ctree: A Compact Tree for Indexing XML Data. In
Proceedings of 6th International Workshop on Web Information and Data Management
(WIDM), 2004.PDF
4.2 Presentations & Posters
- "CoXML: A Cooperative XML Query Answering System", UCLA Engineering Annual Research Review, 2006.(Poster abstract in pdf format)
- "Query Relaxation for XML Databases",
NSF IDM 04 Workshop,
Cambridge, Massachusetts, Oct. 10 - Oct. 12th, 2004.(Poster in power point
format)
- "Query Relaxation for XML Databases",
NSF IDM 03 Workshop,
Seattle, Washington, Sept. 14- Sept. 16, 2003. (Presentation in
power point format)
4.3 Master Comprehensive Exam Reports
- Tony Lee. Indexing Technique for XML structure patterns.
MaSters Thesis, Computer Science Department, UCLA, Winter 2003. PDF
- Eric Sung. Parser for Relaxation-Enabled XML Query Language.
Masters Thesis, Computer Science Department, UCLA, Fall 2004. PDF
- Christian Cardenas. Parsing and Preprocessing of RLXQuery for XML Query
Relaxation. Masters Thesis, Computer Science Department, UCLA, Spring
2004. PDF
- Anna Putnam. The Relaxation Manager for XML Query Relaxation. Masters Thesis,
Computer Science Department, UCLA, Spring 2004.
PDF
|
