
|
| || Home || Projects || Publications || Members || |
| PhenoMining | SNRS | ISP | CoXML | KMeX | KMeD | CoBase | Data Mining |
A Social Network-Based Recommender System1. MotivationIn order to overcome information overload, recommender systems have become a key tool for providing users with personalized recommendations on items such as movies, music, books, news, and web pages. Despite the improvement over the last decades, recommender systems still face many challenges such as further improving the prediction accuracy, the data-sparsity problem, and the cold-start problem. In this study we try to solve these problems by proposing a new paradigm of recommender systems. This sytem predicts user ratings by utilizing information in social networks, especially that of social influence.Traditional recommender systems do not take into consideration explicit social relations among users, yet the importance of social influence in product marketing has long been recognized. Intuitively, when we want to buy a product that is not familiar, we often consult with our friends who have already had experience with the product, since they are those that we can reach for immediate advice. When friends recommend a product to us, we also tend to accept the recommendation because their inputs are trustworthy. Additionally, the integration of social networks can theoretically improve the performance of current recommender systems. First, in terms of the prediction accuracy, the additional information about users and their friends obtained from social networks improves the understanding of user behaviors and ratings. Therefore, we can model and interpret user preferences more precisely, and thus improve the prediction accuracy. Second, with friend information in social networks, it is no longer necessary to find similar users by measuring their rating similarity, because the fact that two people are friends already indicates that they have things in common. Thus, the data sparsity problem can be alleviated. Finally, for the cold-start issue, even if a user has no past reviews, recommender system still can make recommendations to the user based on the preferences of his/her friends if it integrates with social networks. All of these intuitions and observations motivate us to design a new paradigm of recommender systems that can take advantage of information in social networks. 2. Project SummaryA customer's buying decision can be illustrated by the figure below. Intuitively, this decision is decided by both the customer's own preference for similar items and his/her knowledge about the characteristics of the recommended item. Knowledge about the recommended item can be obtained from two sources: First, public media such as magazines, television, and the Internet where we know the item's general acceptance; Second, the feedbacks or influences from friends which are often more trustworthy than advertisements. Note that this influence is not limited to that from our immediate friends -- our friends within the first hop in a social network graph. Distant friends, i.e., our friends at multiple hops away, can also cast their influence indirectly to us. If the impact from all of the above factors is positive, it is very likely that the target user will select the item. On the contrary, if any has a negative influence, e.g., very low ratings in other user reviews, the chance that the target user will select the item will decrease.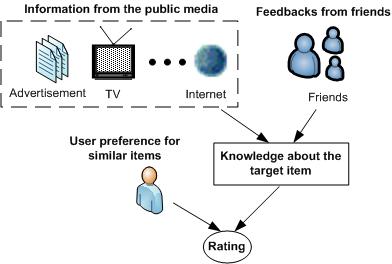 With such an understanding in mind, we designed an algorithm framework which makes personalized recommendations based on the above three factors: customer's own preference, item's general acceptance, and influences from social friends. In particular, we proposed to model the correlations between immediate friends with the histogram of friend's rating differences. The influences from distant friends are also considered in an iterative classification. In addition, we crawled a real online social network from Yelp.com. The analysis on this dataset reveals that friends have a tendency to review the same restaurants and give similar ratings, and friends' ratings become closer as the number of co-rated restaurants increases. We compared the performance of SNRS with other methods, such as collaborative filtering (CF), friend average (FA), weighted friends (WVF) and naive Bayes (NB) with the same dataset. In terms of the prediction accuracy, SNRS achieves the best result. It yields a 17.8% improvement compared to that of CF. In the sparsity test, SNRS returns consistently accurate predictions at different values of data sparsity. The coverage of SNRS decreases when the data is sparse but at a slower speed than CF. In the cold-start test, SNRS still performs well. We also studied the role of distant friends in SNRS, and found that by considering the influences from distant friends, the coverage of SNRS can be significantly improved with only a minor reduction in the prediction accuracy. The performance of SNRS can be further improved by selecting relevant friends for inference, which can be achieved by collecting the semantics of the friend relationships or fine-grained user ratings. Such an approach can be adopted by current content providers. 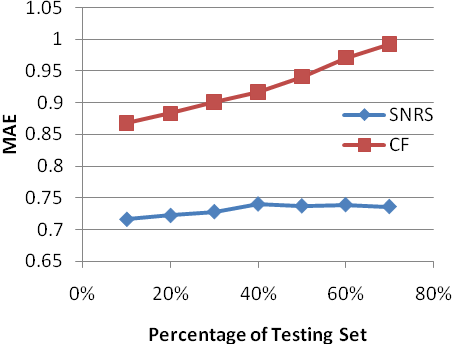 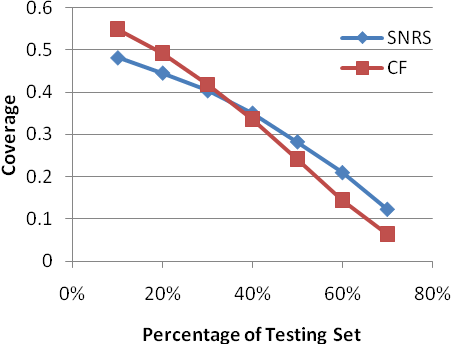 References:
|
|
Powered by CoBase Research Group Last updated on May 21, 2009 |